
Dify实践手册
💡 平时使用Dify有点多,我在这里记录一下我日常遇到的有关Dify 的使用经验,方便日后查阅
如何控制知识库的访问权限
一、背景
在Dify 的设计中,知识库在管理端是有权限的,但是在用户调用接口的时候是没有权限控制的,作为LLMOps确实也不需要控制知识库的权限,因为上层还有应用服务可以控制,但应用层控制也略显麻烦,所以我们也可以尝试自己在Dify中来实现怎么实现对知识库的访问控制。
二、方案
2.1 按照角色进行权限分配
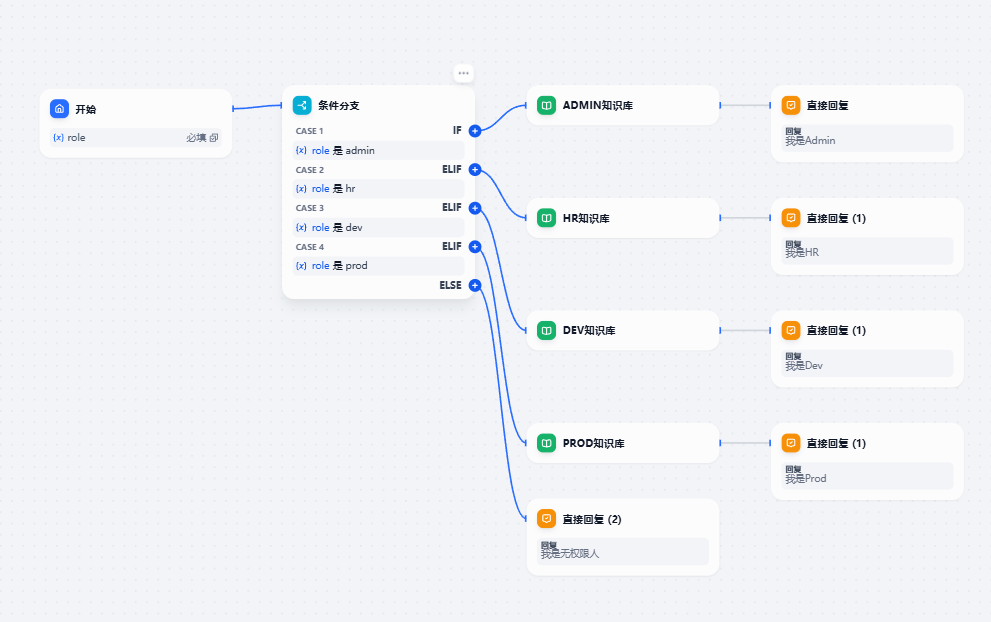
在这个案例中用户只有一种角色,一种角色只能访问一个知识库,在接口中传入对应的角色名称就可以进行过滤。
在这个方案中我采用了条件判断的方式,进行依次对比,同时我们可以使用迭代的方式进行轮训。效果都是一样的
步骤:
-
输入角色
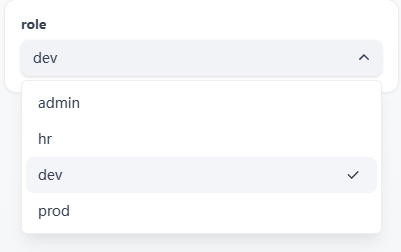
-
输入问题
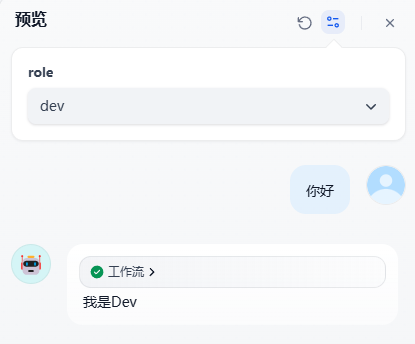
流程展示:
2.2 按照多个角色进行权限分配
在这个方案中,用户可能包含多个角色,例如一名员工可以同时是HR和开发者,也可以同时是产品经理。
在这个方案中,我采用了并发与条件节点帮我完成,我们也可以使用数组结合迭代来进行流程设计。
步骤:
-
输入多个角色名称
-
进行回答
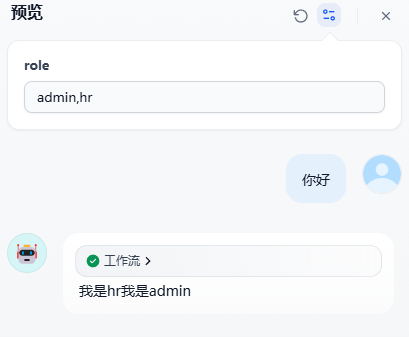
流程展示:
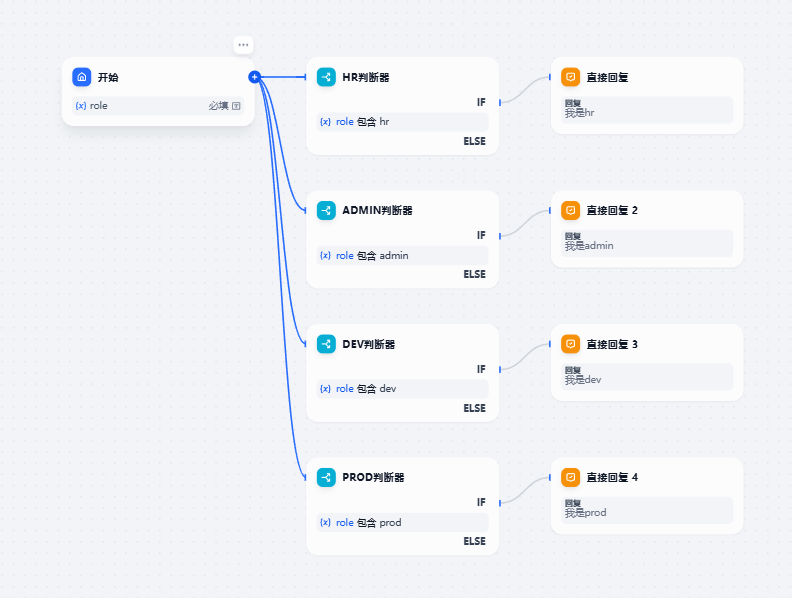
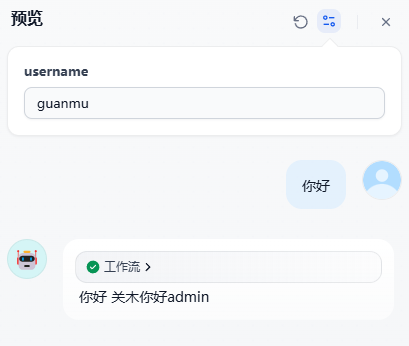
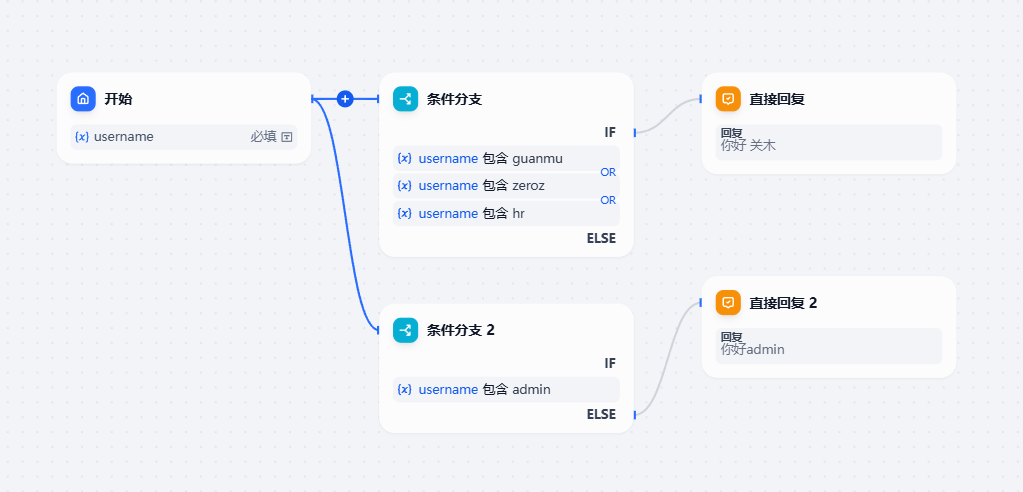
2.3 按照用户名进行权限分配
在这个场景下,我采用用户名的方式,每一个流程前设置一个判断用户名的节点,只有符合用户名的节点才能将流程进行下下去
步骤:
- 输入你的用户名
- 进行提问
- 获得答案
流程图:
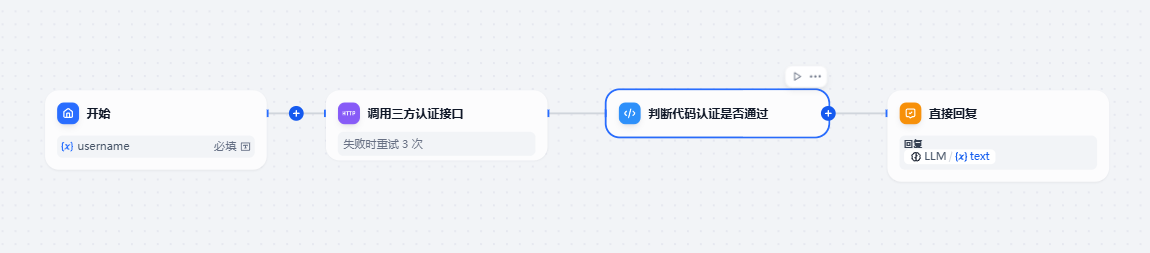
2.4 按照外部接口进行权限分配
有时候我们可以依赖一个外部接口或者一个算法进行用户权限的验证,在这里我们可以采用调用第三方接口的方式,也可以采用代码执行器的方式。
步骤
- 输入用户名
- 进行提问
- 调用认真接口
- 获得答案
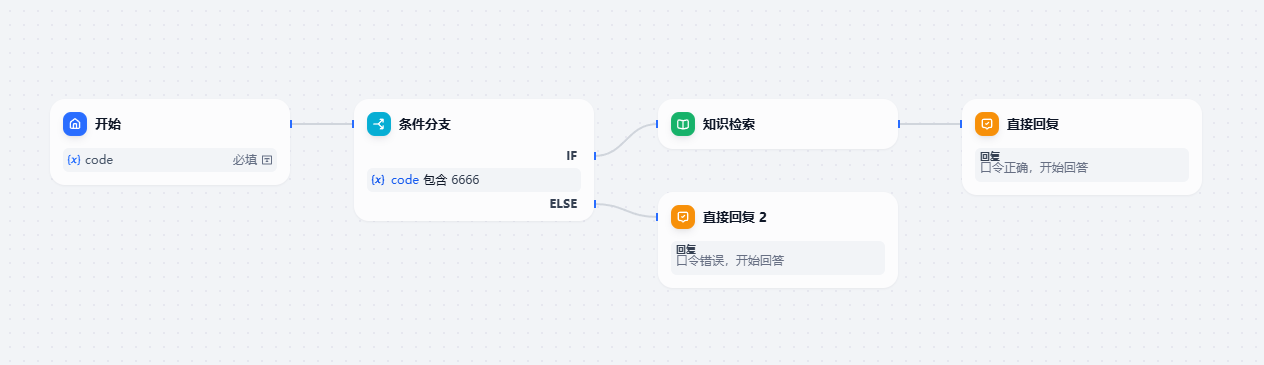
2.5 按照口令进行权限分配
我们使用过类似百度网盘的提取码,我们可以直接分配一个提取码,只要用户提供符合的口令,就可以获得相应的权限
步骤
- 输入口令
- 口令校验
- 获得知识库
- 答案生成
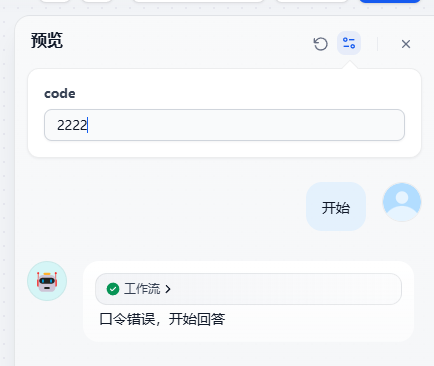
错误口令状态
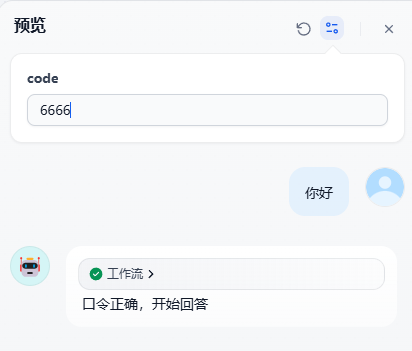
口令正确
流程图
三、结束语
Dify丰富的条件语句为我们提供了非常方便进行权限控制的能力。我们只需要拖动下流程,就能完成我们基础的权限控制需求。
如何在RAG系统中使用记忆
一、背景
在我们使用Dify的时候,我们如果按照官方的教程,将上下文放置到system prompt中,我们会发现,如果多询问几次,后面的资料就会替代原来召回的内容,下面我举一个例子进行说明。
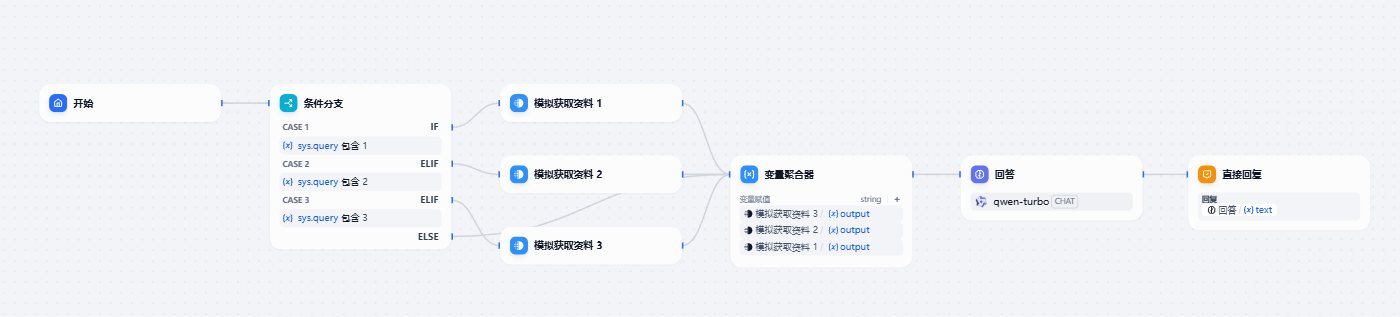
在这个流程中我模拟了不同的问题取回不同材料的流程。
- 如果输入包含“1”的问题,则从模拟资料1中获取。如果输入包含“2”的问题,则从模拟资料2中获取。以此类推
- 我按照要求开启了记忆功能。将获取的资料作为上下文放置到system中去。
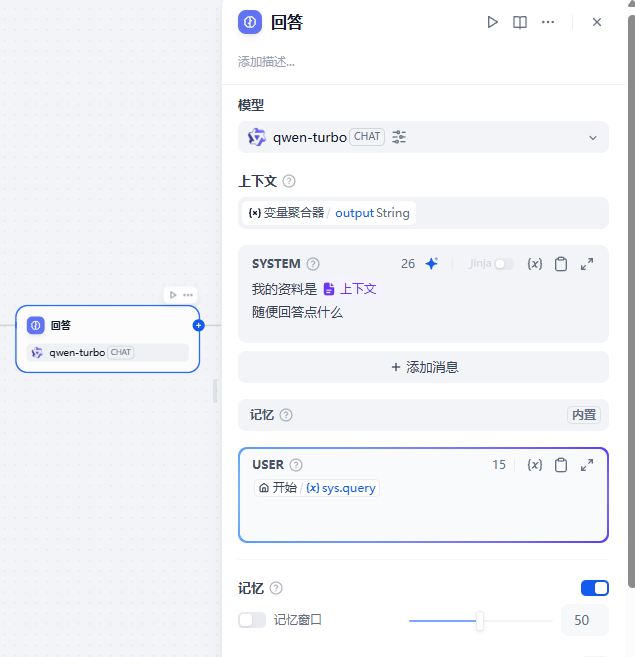
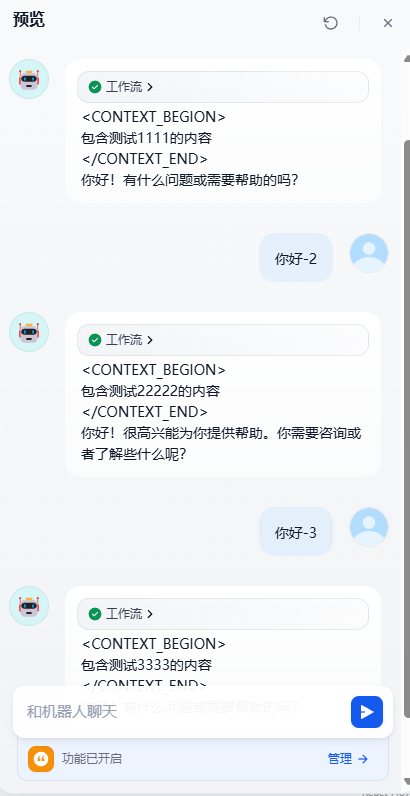
现在我们开始展开三轮对话,我会分别输入问题“你好-1”,“你好-2”,“你好-3”,让我们来进行观察。
阶段一:输入问题“你好-1”
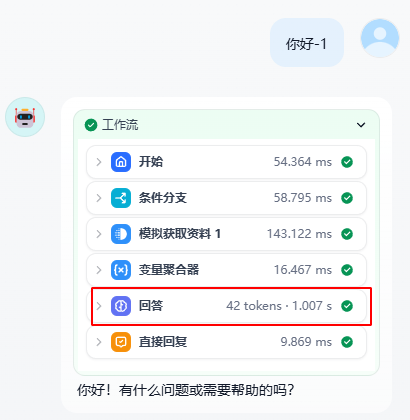
流程成功进行,我们来查看回答这个节点的数据处理
{
"model_mode": "chat",
"prompts": [
{
"role": "system",
"text": "我的资料是{包含测试1111的内容}\n随便回答点什么",
"files": []
},
{
"role": "user",
"text": "你好-1",
"files": []
}
],
"model_provider": "langgenius/tongyi/tongyi",
"model_name": "qwen-turbo"
}在该流程中,我们开单到了资料成功获取,并进行了提问。
阶段二:输入问题“你好-2”
阶段二流程完成以后,我们继续查看节点的数据处理
{
"model_mode": "chat",
"prompts": [
{
"role": "system",
"text": "我的资料是{包含测试22222的内容}\n随便回答点什么",
"files": []
},
{
"role": "user",
"text": "你好-1",
"files": []
},
{
"role": "assistant",
"text": "你好!有什么问题或需要帮助的吗?",
"files": []
},
{
"role": "user",
"text": "你好-2",
"files": []
}
],
"model_provider": "langgenius/tongyi/tongyi",
"model_name": "qwen-turbo"
}我们发现了system prompt 中的 资料被替换成了 资料库2中的内容,资料1 的内容完全消失了。
阶段三:输入问题“你好-3”
阶段三流程完成以后,我们继续查看节点的数据处理
{
"model_mode": "chat",
"prompts": [
{
"role": "system",
"text": "我的资料是{包含测试3333的内容}\n随便回答点什么",
"files": []
},
{
"role": "user",
"text": "你好-1",
"files": []
},
{
"role": "assistant",
"text": "你好!有什么问题或需要帮助的吗?",
"files": []
},
{
"role": "user",
"text": "你好-2",
"files": []
},
{
"role": "assistant",
"text": "你好!很高兴能为你提供帮助。你需要咨询或者讨论些什么呢?",
"files": []
},
{
"role": "user",
"text": "你好-3",
"files": []
}
],
"model_provider": "langgenius/tongyi/tongyi",
"model_name": "qwen-turbo"
}我们发现了system prompt 中的 资料被替换成了 资料库3中的内容,资料1 和资料2中的的内容完全消失了。
阶段总结
通过刚才的实验我们发现Dify在处理对话流程的时候,会使用最新的资料代替system promp中资料的部分,会造成资料的丢失,尤其当我们需要在对话中涉及到产品对比,第一条资料和第二条资料对比的时候,资料就会丢失。
解决方案
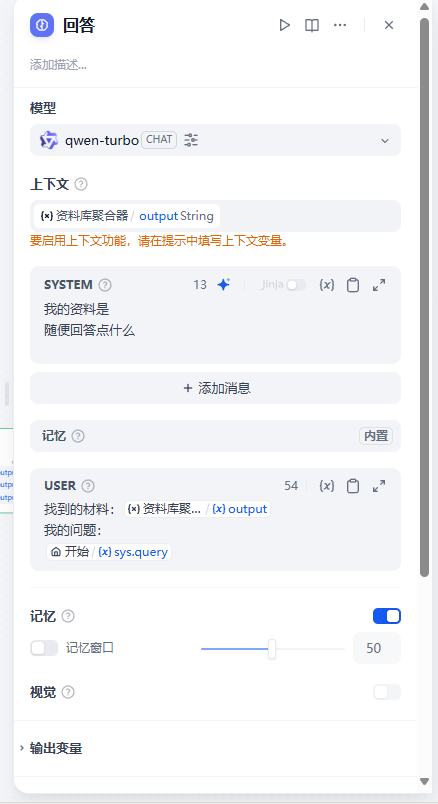
方案一:在输出的时候带上原来的资料
既然我们system prompt无法记录原先找到的内容,那么我们是否可以将材料记录到问题中呢?
{
"model_mode": "chat",
"prompts": [
{
"role": "system",
"text": "我的资料是\n随便回答点什么",
"files": []
},
{
"role": "user",
"text": "1",
"files": []
},
{
"role": "assistant",
"text": "找到的资料:\n包含测试1111的内容\n看起来你正在寻找一些与“测试1111”相关的信息或结果。虽然我手头的资料有限,无法直接提供关于“测试1111”的具体内容,但通常这样的术语可能指的是某种特定的测试、实验或者评估过程的编号。如果你能提供更多背景信息或是具体想了解哪方面的内容,我会尽力帮助你找到相关信息或给出更具体的建议。例如,这可能是软件测试的一部分,也可能是某种学术研究中的步骤编号等。请告诉我更多细节,好吗?",
"files": []
},
{
"role": "user",
"text": "2",
"files": []
},
{
"role": "assistant",
"text": "看起来您提到的是一个包含“测试22222”的材料,不过您似乎还没有具体说明您的问题是什么。如果您能提供更多详细信息,比如您想了解这个测试的具体内容、目的或者是如何进行的等等,我将能够更好地为您提供帮助。\n\n如果“测试22222”是指某个特定领域的测试(如软件测试、心理测试、教育测试等),提供更多的上下文会非常有帮助。这样我可以更有针对性地为您查找相关信息或解答您的疑问。\n\n请告诉我您具体想了解什么,好吗?",
"files": []
},
{
"role": "user",
"text": "找到的材料:包含测试3333的内容\n我的问题:\n3",
"files": []
}
],
"model_provider": "langgenius/tongyi/tongyi",
"model_name": "qwen-turbo"
}经过测试,Dify不会按照我们的user格式进行请求,只会按照用户的请求数据构造。
那我们将找到的资料放到输出的内容是不是可行?
我们直接试一试
第一步:先进行LLM节点的设置
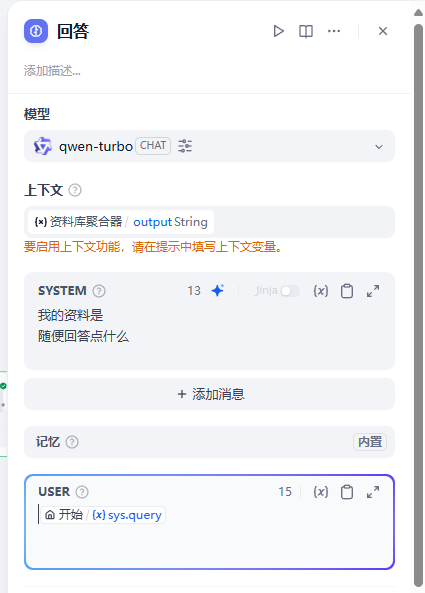
第二步:设置最后䣌输出节点
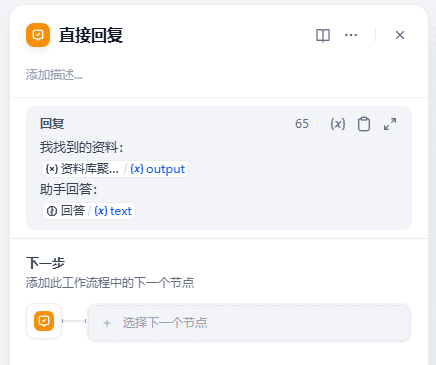
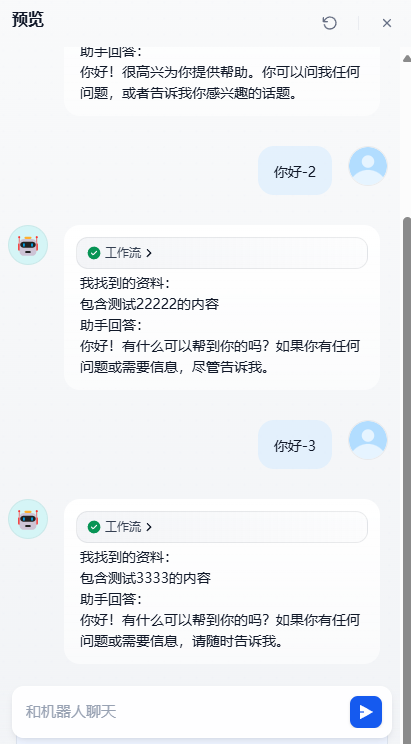
第三步:开始测试,查看多轮对话以后的数据变化
{
"model_mode": "chat",
"prompts": [
{
"role": "system",
"text": "我的资料是\n随便回答点什么",
"files": []
},
{
"role": "user",
"text": "你好-1",
"files": []
},
{
"role": "assistant",
"text": "我找到的资料:\n包含测试1111的内容\n助手回答:\n你好!很高兴为你提供帮助。你可以问我任何问题,或者告诉我你感兴趣的话题。",
"files": []
},
{
"role": "user",
"text": "你好-2",
"files": []
},
{
"role": "assistant",
"text": "我找到的资料:\n包含测试22222的内容\n助手回答:\n你好!有什么可以帮到你的吗?如果你有任何问题或需要信息,尽管告诉我。",
"files": []
},
{
"role": "user",
"text": "你好-3",
"files": []
}
],
"model_provider": "langgenius/tongyi/tongyi",
"model_name": "qwen-turbo"
}查看日志,我们发现assistant的节点包含了我们找到的内容。
说明这样的方案是可行的。对话中保留了原来找到资料的内容。
这样的展示太影响展示了。我们可以设置自定义的标签,方便客户端去处理
例如
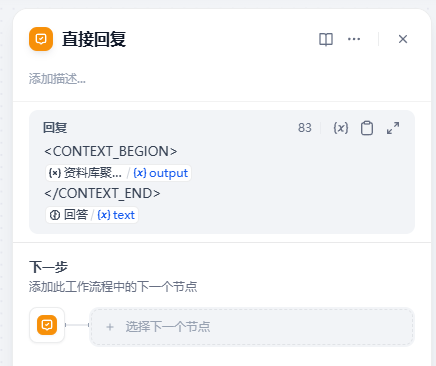
在这个例子中我们将查找到的资料放置到
只要我们和客户端约定好数据结构,客户端也就能实现类似资料索引的效果了。这样的数据可以是文本、也可以是视频和图片,

方案二:通过变量赋值实现召回数据的写入
在Dify中有一个会话变量的参数,他能够帮助我们储存一些信息。我们可以实现一个小型的召回资料的存储器。
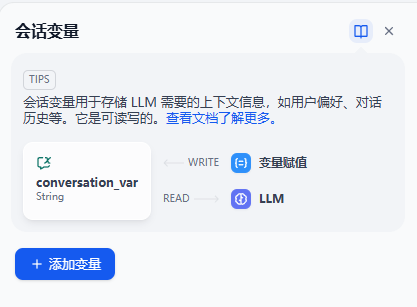
我们可以通过设置一个名叫 storage的变量来进行数据的存储。

然后我们增加流程

代码执行主要工作是保证存储只保留最新的4条记录
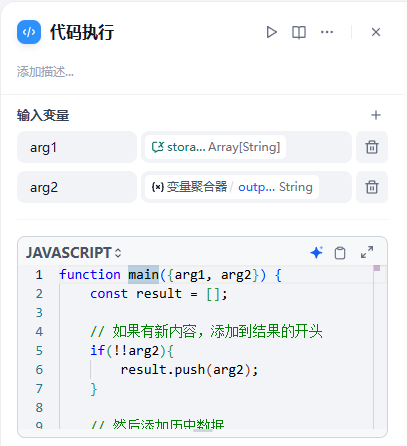
function main({arg1, arg2}) {
const result = [];
// 如果有新内容,添加到结果的开头
if(!!arg2){
result.push(arg2);
}
// 然后添加历史数据
if(Array.isArray(arg1)) {
result.push(...arg1);
}
// 只保留最新的4条数据
return {
result: result.slice(0, 4)
}
}处理完以后就加入到会话变量中
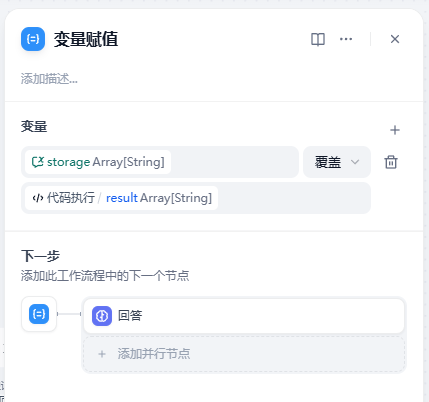
我们开始最后的测试
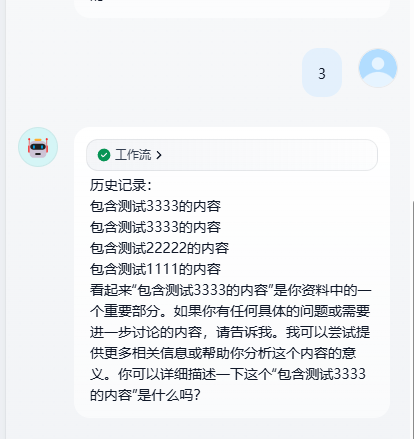
对话记录
{
"model_mode": "chat",
"prompts": [
{
"role": "system",
"text": "我的资料是{包含测试3333的内容\n包含测试3333的内容\n包含测试22222的内容\n包含测试1111的内容}\n随便回答点什么",
"files": []
},
{
"role": "user",
"text": "1",
"files": []
},
{
"role": "assistant",
"text": "历史记录:\n包含测试1111的内容\n你的资料提到“包含测试1111的内容”,让我很感兴趣呢。不过我更想听听这测试1111具体是什么,是某种神秘的代码还是有趣的实验结果呀?",
"files": []
},
{
"role": "user",
"text": "2",
"files": []
},
{
"role": "assistant",
"text": "历史记录:\n包含测试22222的内容\n包含测试1111的内容\n看起来你可能对某些特定的信息或内容感兴趣。如果你有任何问题或者需要讨论某个话题,请告诉我更多细节,我会尽力提供帮助或进行相关的讨论。无论是关于“包含测试1111的内容”还是其他任何主题,都欢迎你分享更多信息!",
"files": []
},
{
"role": "user",
"text": "3",
"files": []
},
{
"role": "assistant",
"text": "历史记录:\n包含测试3333的内容\n包含测试22222的内容\n包含测试1111的内容\n历史记录:\n包含测试3333的内容\n包含测试22222的内容\n包含测试1111的内容\n\n从你的资料来看,“包含测试3333的内容”似乎是一个特别的条目。你是否希望了解更多关于这个内容的信息,或者有其他方面想要探讨的?",
"files": []
},
{
"role": "user",
"text": "3",
"files": []
}
],
"model_provider": "langgenius/tongyi/tongyi",
"model_name": "qwen-turbo"
}我们发现对话中的system promp 就包含了最新获取的资料,
这样就保证了连续对话的时候最新搜索到资料不会覆盖原有查找到的内容。
但是遇到一个问题,如果内容太多怎么办呢?或者说我们是否可以总结以往的对话?
方案三:召回资料总结
有时候我们还需要对召回的资料进行总结,这样的优势
- 减少召回资料上下文的长度
- 针对问题和资料进行总结,更加聚焦
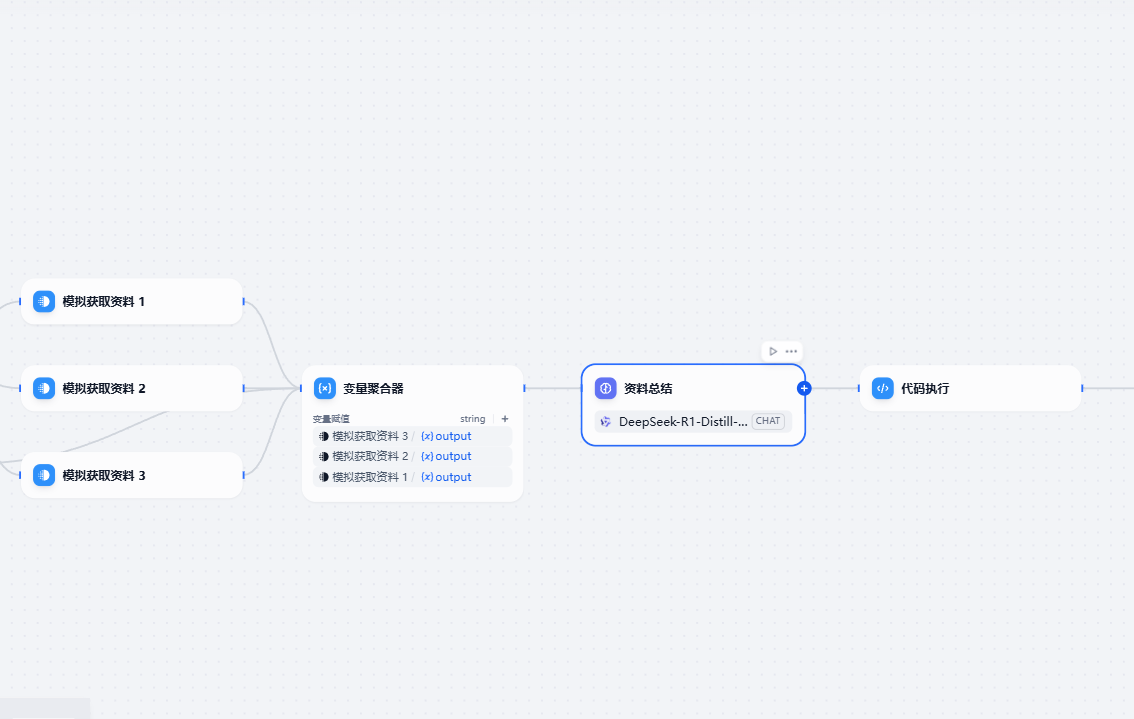
增加可以增加LLM总结节点
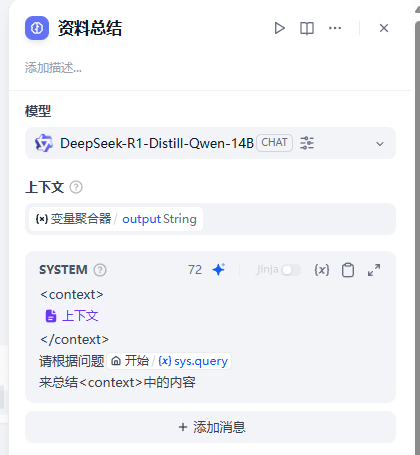
这样,我们就完成了一个初版的资料记忆的功能。

方案四:对话总结功能
召回的资料既然能总结,我们是否对历史的对话记录也可以进行总结。这样在一定程度保证对话的连贯性。
在Dify中提供了记忆的功能,但是只提供了窗口的功能,无法做到总结对话历史,那我们可以自己实现。
首先,我们增加一个变量就叫 summary
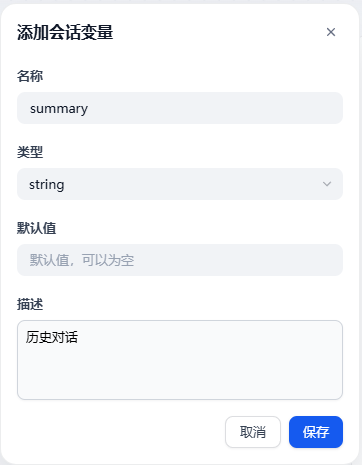
让我们来设计一条链路来处理历史记录
- 可以是并行任务,这样需要在下次聊天的时候才会了解前面的内容,这样并发请求,不影响主流程的进度
- 也可以是穿行任务,这样总结,总结内容会及时插入,可能需要多一次llm的请求
我们按照并发任务开始
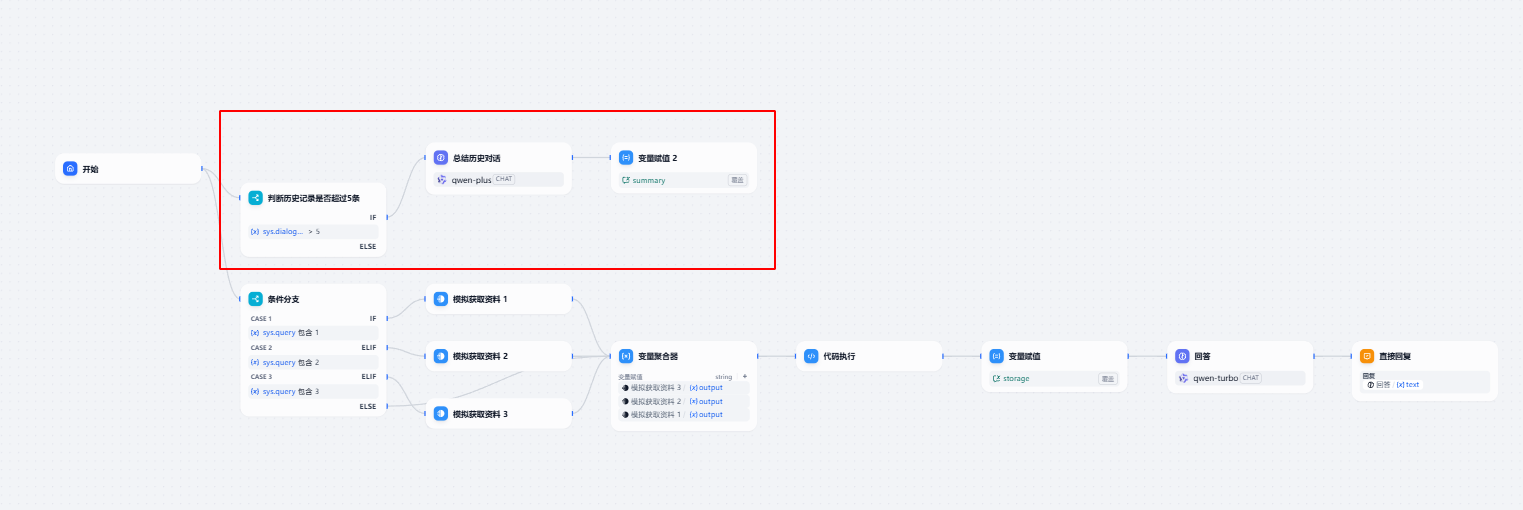
在上图中,我么能增加了一路保存历史总结的内容,我们在对话超过5次的时候自动总结。
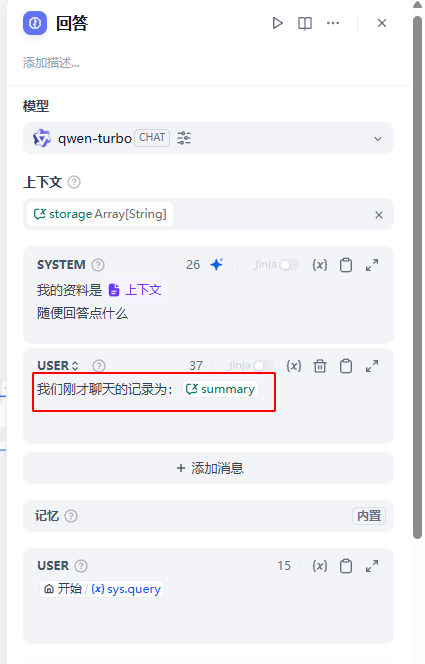
在回答的文档中,我们增加了历史记录的信息
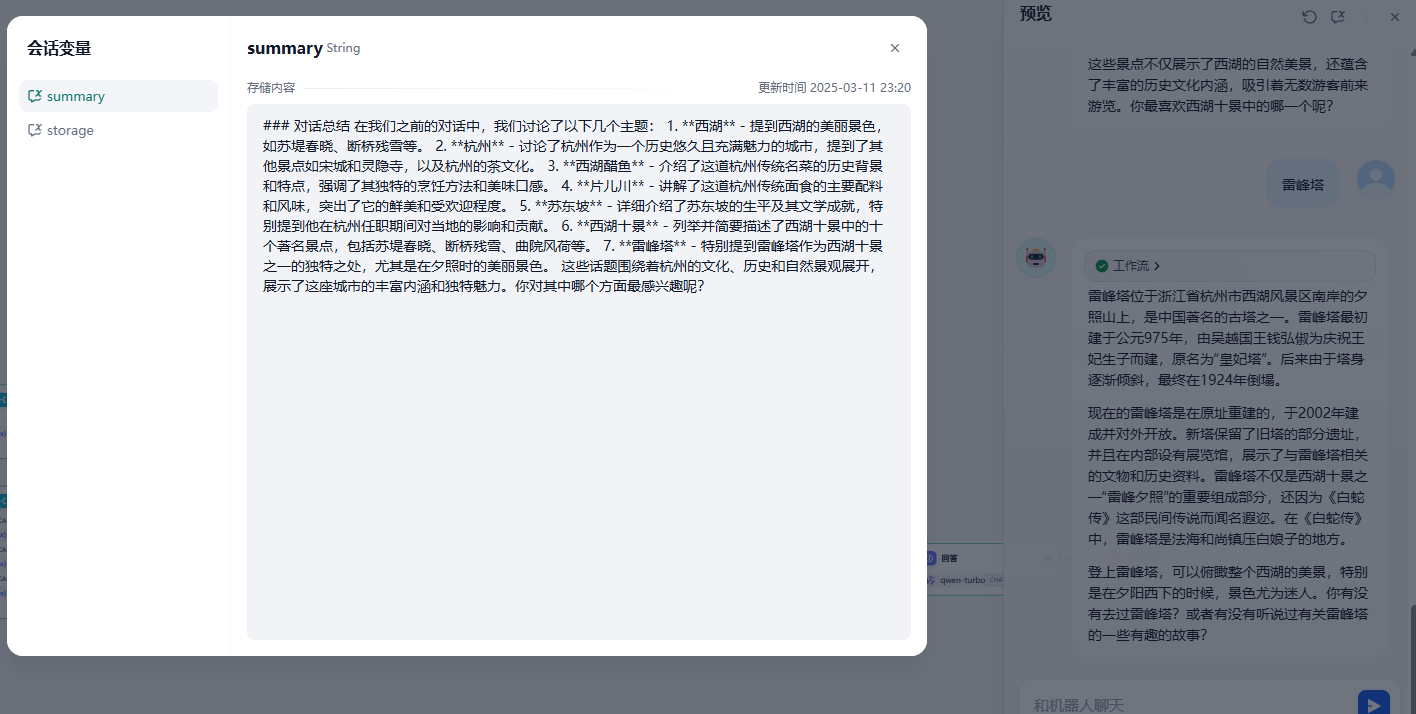
现在让我们来测试下,我们围绕西湖、杭州、西湖醋鱼片儿川等问题进行了提问。在变量中我们也看到了dify成功的存储了对话总结
我们再来看看请求的日志
{
"model_mode": "chat",
"prompts": [
{
"role": "system",
"text": "我的资料是{{#context#}}\n随便回答点什么",
"files": []
},
{
"role": "user",
"text": "我们刚才聊天的记录为:### 对话总结\n\n在我们之前的对话中,我们讨论了以下几个主题:\n\n1. **西湖**\n - 提到西湖的美丽景色,如苏堤春晓、断桥残雪等。\n\n2. **杭州**\n - 讨论了杭州作为一个历史悠久且充满魅力的城市,提到了其他景点如宋城和灵隐寺,以及杭州的茶文化。\n\n3. **西湖醋鱼**\n - 介绍了这道杭州传统名菜的历史背景和特点,强调了其独特的烹饪方法和美味口感。\n\n4. **片儿川**\n - 讲解了这道杭州传统面食的主要配料和风味,突出了它的鲜美和受欢迎程度。\n\n5. **苏东坡**\n - 详细介绍了苏东坡的生平及其文学成就,特别提到他在杭州任职期间对当地的影响和贡献。\n\n6. **西湖十景**\n - 列举并简要描述了西湖十景中的十个著名景点,包括苏堤春晓、断桥残雪、曲院风荷等。\n\n7. **雷峰塔**\n - 特别提到雷峰塔作为西湖十景之一的独特之处,尤其是在夕照时的美丽景色。\n\n这些话题围绕着杭州的文化、历史和自然景观展开,展示了这座城市的丰富内涵和独特魅力。你对其中哪个方面最感兴趣呢?",
"files": []
},
{
"role": "user",
"text": "西湖",
"files": []
},
{
"role": "assistant",
"text": "西湖真的很美呢,尤其是苏堤春晓、断桥残雪这些著名景色。你去过西湖吗?或者有什么关于西湖的故事想分享吗🧐",
"files": []
},
{
"role": "user",
"text": "杭州",
"files": []
},
{
"role": "assistant",
"text": "杭州是一个历史悠久且充满魅力的城市,除了著名的西湖之外,还有许多其他的旅游景点和文化特色。比如宋城可以体验宋代的文化氛围,灵隐寺则是一个非常有名的佛教圣地。此外,杭州还是茶文化的重要代表,龙井茶就是这里的特产之一。你对杭州的哪个方面最感兴趣呢?",
"files": []
},
{
"role": "user",
"text": "西湖醋鱼",
"files": []
},
{
"role": "assistant",
"text": "西湖醋鱼是一道非常有特色的杭州传统名菜。这道菜选用的是草鱼,通过特殊的烹饪手法,使得鱼肉嫩滑,酸甜适口,非常美味。据说这道菜的历史可以追溯到南宋时期,至今仍然深受人们的喜爱。\n\n如果你有机会去杭州,一定不要错过品尝这道地道的杭州美食。你在尝试过西湖醋鱼之后有什么感想吗?或者你有没有什么做这道菜的小秘诀想要分享呢?",
"files": []
},
{
"role": "user",
"text": "片儿川",
"files": []
},
{
"role": "assistant",
"text": "片儿川是杭州非常有名的一种传统面食,以其独特的风味和制作工艺受到很多人的喜爱。它主要由细长的面条配上雪菜(即腌制的白菜)、笋片和瘦肉丝组成。汤头鲜美,面条滑爽,配料丰富,味道层次分明,既可作为主食饱腹,也是一道美味的菜肴。\n\n如果你喜欢面食的话,片儿川绝对值得一试。你平时还喜欢吃哪些面食呢?或者你有没有自己特别钟爱的家乡小吃?",
"files": []
},
{
"role": "user",
"text": "苏东坡",
"files": []
},
{
"role": "assistant",
"text": "苏东坡(1037年—1101年),字子瞻,号东坡居士,是北宋时期著名的文学家、书画家,也是唐宋八大家之一。他的文学成就非常高,诗词、散文都有卓越的表现,尤其以豪放派诗词著称。苏东坡不仅在文学上有很高的造诣,在书法和绘画上也有极高的成就。\n\n苏东坡一生经历坎坷,曾多次被贬官,但他始终保持乐观豁达的人生态度,留下了许多脍炙人口的作品。他的作品中常常流露出对自然美景的热爱以及对生活的深刻感悟,如《赤壁赋》、《念奴娇·赤壁怀古》等。\n\n苏东坡与杭州也有很深的渊源,他曾担任杭州的地方官,并在此期间为当地做了不少好事,留下了诸多佳话。你对苏东坡有哪些了解或特别感兴趣的地方呢?",
"files": []
},
{
"role": "user",
"text": "西湖十景",
"files": []
},
{
"role": "assistant",
"text": "西湖十景是指位于中国浙江省杭州市西湖周边的十个著名景点,每个景点都有其独特的风景和历史背景。这十个景点分别是:\n\n1. **苏堤春晓**:春天时,苏堤两岸的柳树和桃花盛开,景色十分迷人。\n2. **断桥残雪**:冬天雪后,断桥上的积雪与湖面的雾气交相辉映,形成一幅美丽的画面。\n3. **曲院风荷**:夏季荷花盛开,漫步于曲折的小径间,欣赏荷花的美丽。\n4. **平湖秋月**:秋天夜晚,湖面上的月亮倒映,景色宁静而美丽。\n5. **柳浪闻莺**:春天柳树成荫,莺鸟鸣叫,是赏柳听鸟的好地方。\n6. **花港观鱼**:这里有一个小池塘,里面养着各种颜色的金鱼,游客可以喂鱼。\n7. **雷峰夕照**:夕阳西下时,雷峰塔在夕阳的照射下显得格外美丽。\n8. **双峰插云**:两座山峰高耸入云,尤其是在雨后的清晨,云雾缭绕,景色壮观。\n9. **南屏晚钟**:晚上南屏山上净慈寺的钟声响起,回荡在西湖上空,给人以宁静的感觉。\n10. **三潭印月**:三潭映月是西湖的一个小岛,上面有三个石塔,夜晚时分,灯光透过石塔,形成美丽的光影效果。\n\n这些景点不仅展示了西湖的自然美景,还蕴含了丰富的历史文化内涵,吸引着无数游客前来游览。你最喜欢西湖十景中的哪一个呢?",
"files": []
},
{
"role": "user",
"text": "雷峰塔",
"files": []
},
{
"role": "assistant",
"text": "雷峰塔位于浙江省杭州市西湖风景区南岸的夕照山上,是中国著名的古塔之一。雷峰塔最初建于公元975年,由吴越国王钱弘俶为庆祝王妃生子而建,原名为“皇妃塔”。后来由于塔身逐渐倾斜,最终在1924年倒塌。\n\n现在的雷峰塔是在原址重建的,于2002年建成并对外开放。新塔保留了旧塔的部分遗址,并且在内部设有展览馆,展示了与雷峰塔相关的文物和历史资料。雷峰塔不仅是西湖十景之一“雷峰夕照”的重要组成部分,还因为《白蛇传》这部民间传说而闻名遐迩。在《白蛇传》中,雷峰塔是法海和尚镇压白娘子的地方。\n\n登上雷峰塔,可以俯瞰整个西湖的美景,特别是在夕阳西下的时候,景色尤为迷人。你有没有去过雷峰塔?或者有没有听说过有关雷峰塔的一些有趣的故事?",
"files": []
},
{
"role": "user",
"text": "平湖秋月",
"files": []
}
],
"model_provider": "langgenius/tongyi/tongyi",
"model_name": "qwen-turbo"
}我们可以看到在最新一条的user数据中,就有了历史对话的总结
总结
在对话中一些数据的存储可以方便的为我们提供组合数据与对话的能力,在形式上可以分为并发与串行,在储存内容上,我们可以储存历史对话,可以储存召回的资料。核心是赋予我们组装对话的能力。
Dify对话显示效果增强
背景
在Dify 的Web应用中,我们一般来说只能使用markdown的语法,但是markdown的语法本身也是支持html标签的。所以我们可以探索下使用Dify原生的web页面,创建一些更美观的内容。
案例一:简单搜索引用
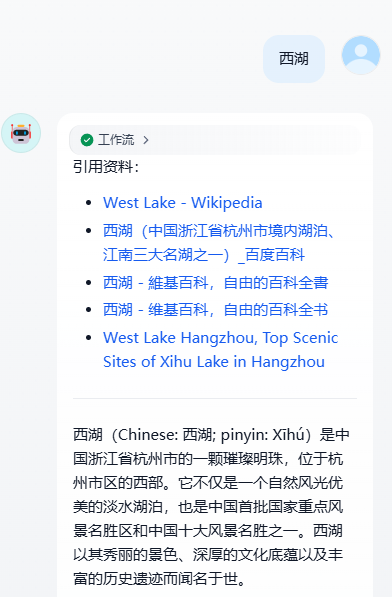
这是一个非常简单的搜索引用的样式,我们只需要稍微配置下节点流程就可以完成。
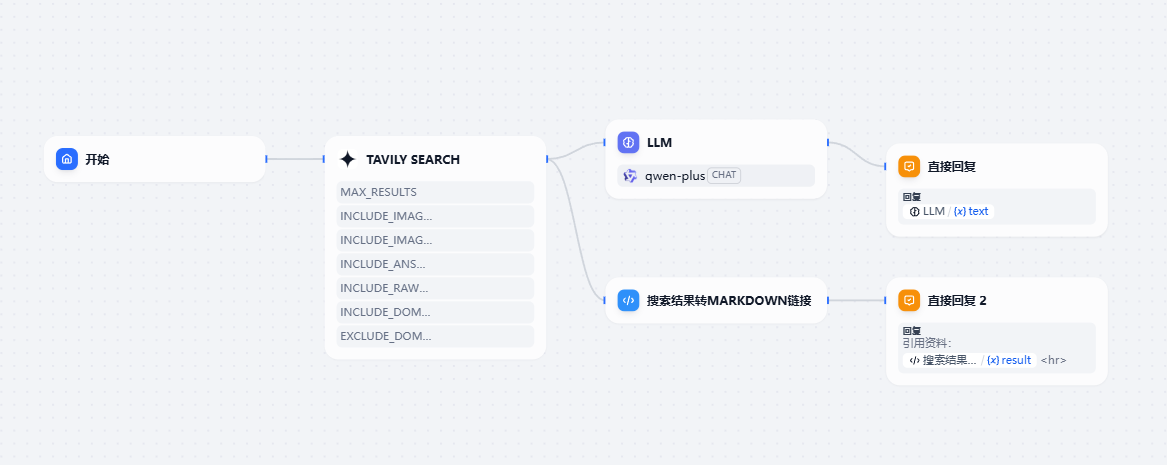
里面包含一个搜索的插件,一个llm回答,一个代码执行器把搜索的结果转成markdown的语法。
案例二:卡片式的引用
刚才我们已经创建了一个最简单的引用展示,那我们能不能更加丰富我们的页面的。
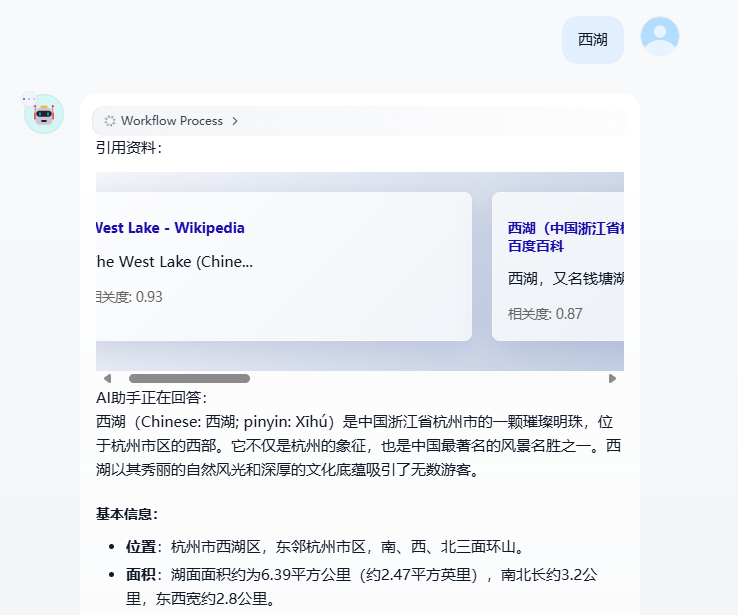
通过努力,我们可以在dify中创建一个可以滚动的引用卡片。
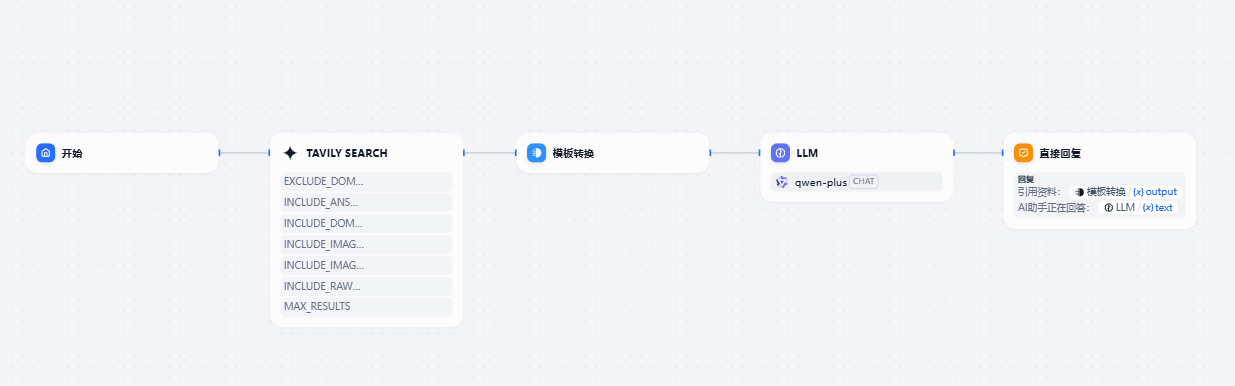
流程非常简单,只是增加了一层模板转换,在模板转换中使用html的结构,在页面就能成功展示了。
案例三:图片展示
前面我们已经可以引用内容和创建卡片式的内容,我们再脑洞大开下,是否可以展示图片了。
实现效果如下:
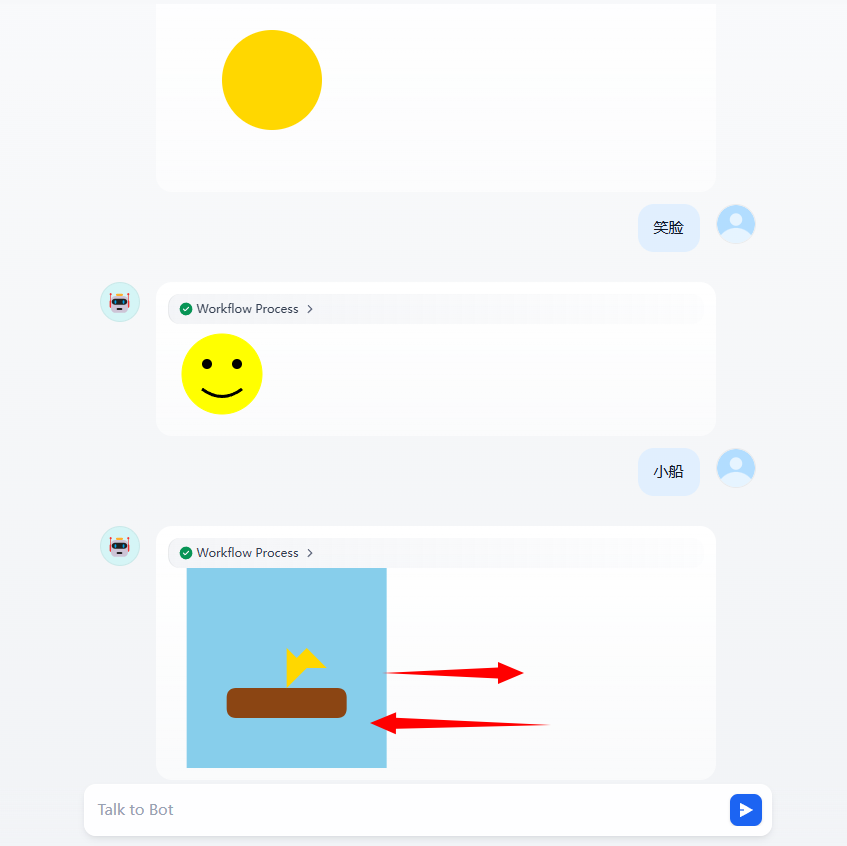
简单的调整,我们就实现了通过文字生成SVG的动画
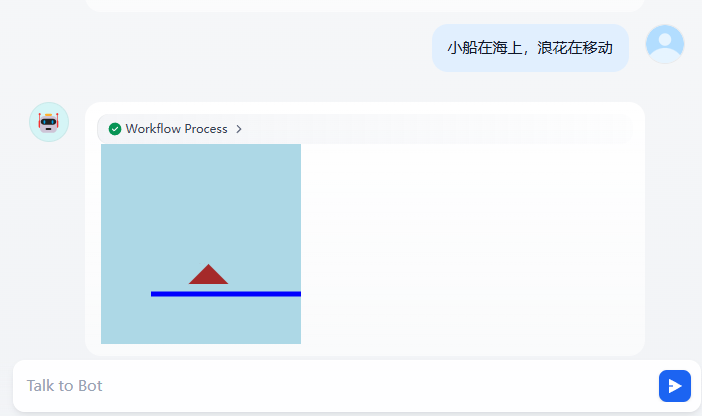
再加上运动的描述,可以直接变成了动画了。实现了一套小Canvas画板。
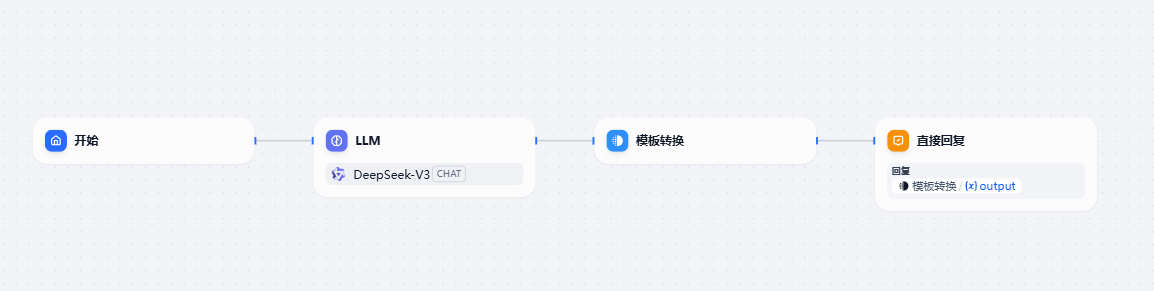
流程也非常的简单,只是通过了模板转换进行了svg代码的输出。
结束
虽然我们通过各类变相的方法实现了各类展示效果,但是还是希望Dify可以提供一个Canvase的输出节点。用来输出给类产出物。
如何使用Dify模板转换节点做Prompt管理
在搭建AI工作流时,Prompt的使用是一个关键环节。
这部分常常被工程背景的开发人员所忽略。
虽然Dify本身没有提供Prompt的专属管理功能,但我们完全可以利用模板转换节点来实现这一目标。
为什么选择模板转换节点?
- 节点具有入参和出参,可以对Prompt Template进行扩展
- 支持纯文本编写,不像代码节点那样需要编程
- 可以结合会话变量、环境变量和上游节点,拓展各类prompt的组合能力
- 一份Prompt可以在多个LLM节点中复用,也可以将多个Prompt组合使用
一些示例:
示例1:简单的文本模板
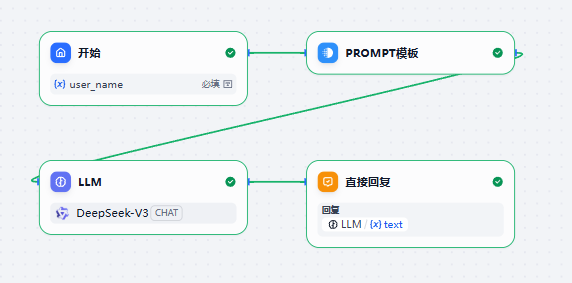
这是一个最简单的里,Prompt通过模板进行管理
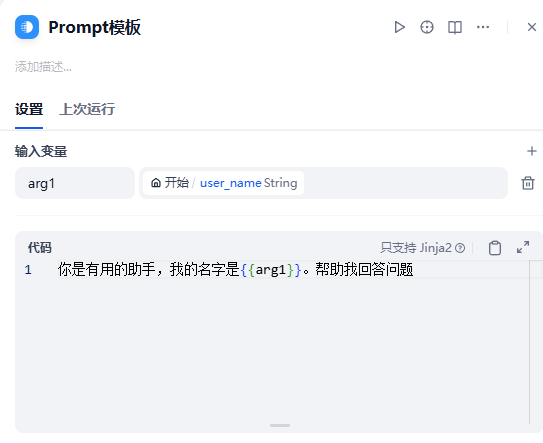
将变量通过Jinja2语法插入到模板中,就可以在LLM节点复用了。
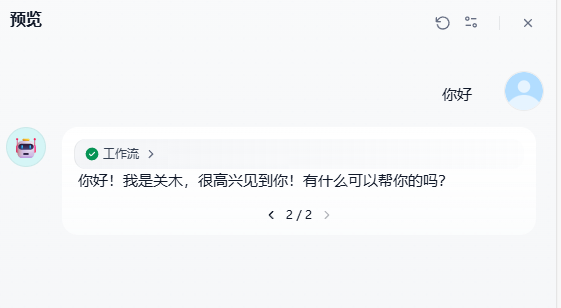
最后,一个简单示例就完成了。
示例2:一份Prompt 模板多个LLM节点使用
在一个工作流中,我们可能需要走不同的LLM节点,这个时候,我们就可以公用一份节点。
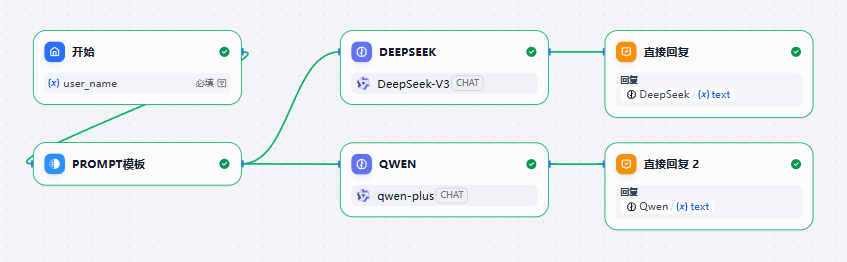
上面的工作流通过并行的方式运行LLM节点,同时保证Prompt相同。
适合的场景:
- 快速调试多个模型
- 多个模型不同参数的对比
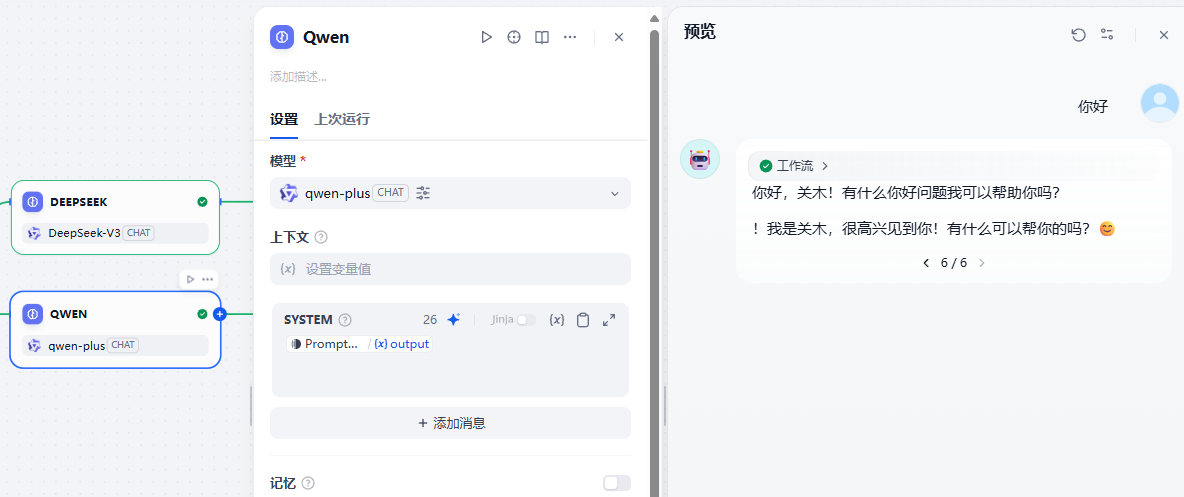
示例3:一份Prompt 模板多个LLM节点使用
我们可以并发使用LLM节点,我们自然也可以结合if-else等节点,通过条件调用不同的LLM,同时只需要维护一个Prompt
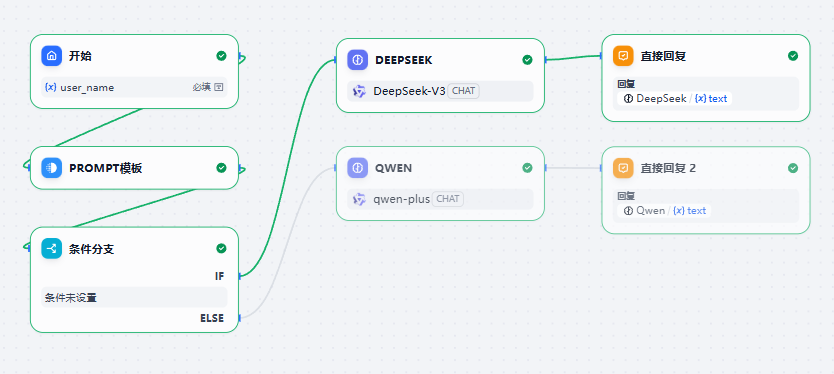
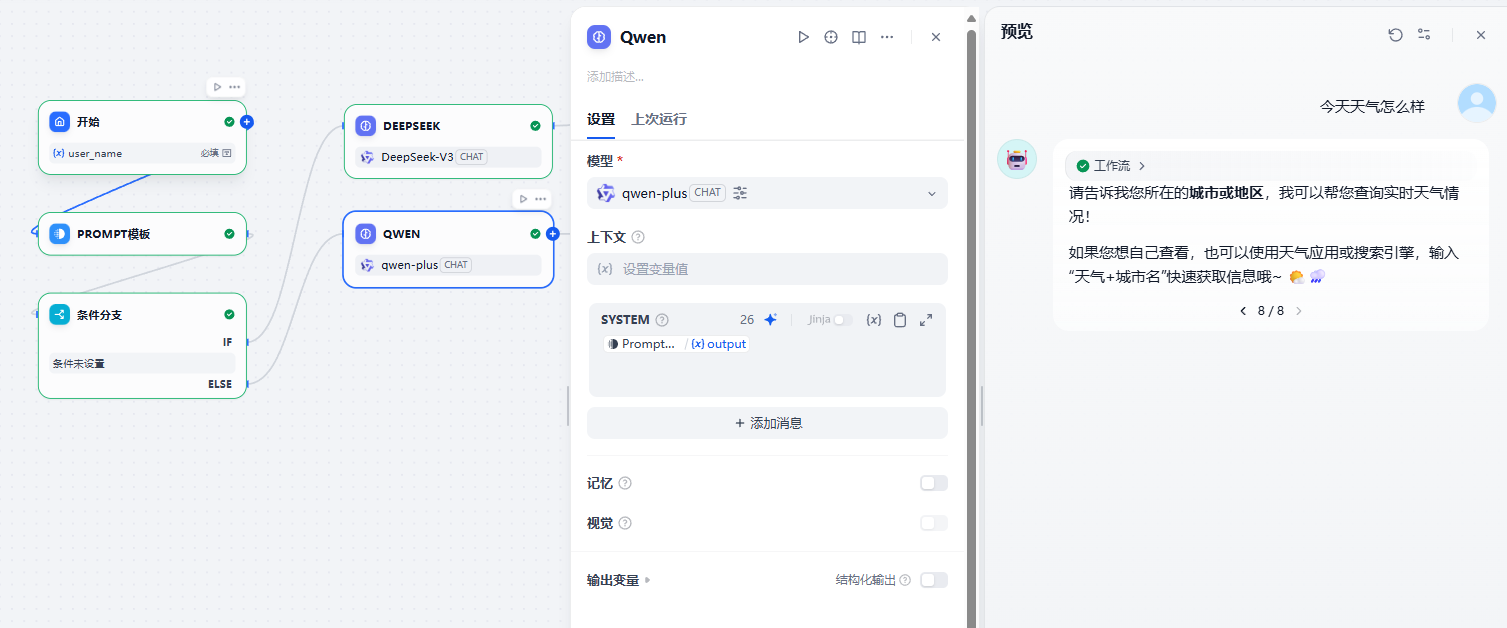
这样,我们就可以通过一些判断节点,分流不同任务到不同的LLM节点。
这里的判断条件可以是入参、环境变量、会话变量等。
示例4:多份Prompt 模板在一个LLM中使用
没有Prompt管理的时候,我们会将Prompt在节点中信息都在LLM节点编写。
如果我们增加了几个功能,可能导致LLM节点中的Prompt混乱,这个时候我们可以通过将功能与Prompt内聚的方式进行管理。
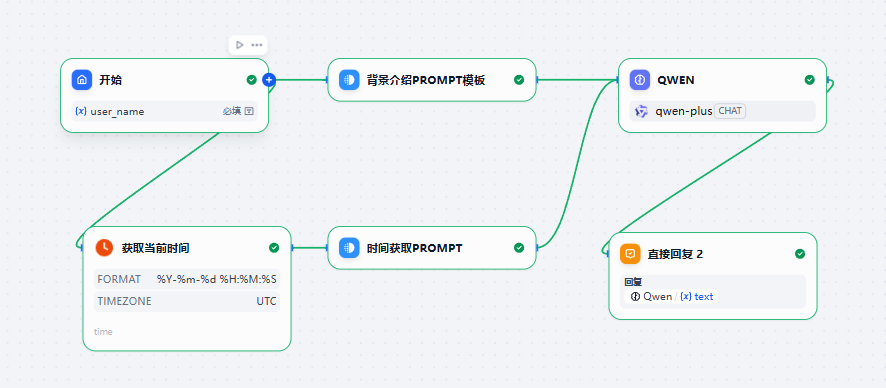
在这个例子中:
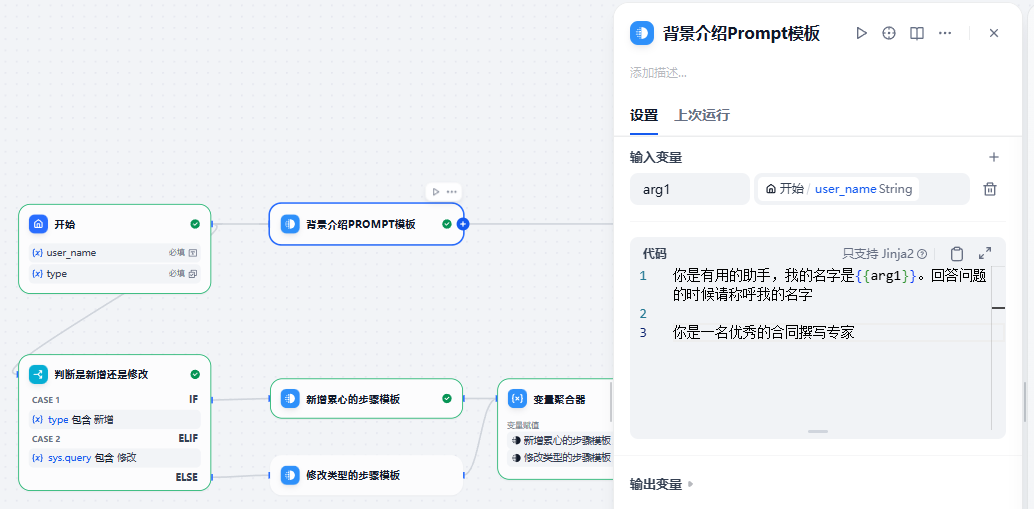
- 背景介绍的Prompt主要是介绍了当前用户的名字
- 获取时间的Prompt主要是返回了当前的时间。
- 在LLM节点,我们只要将提示词进行整合就可以了。
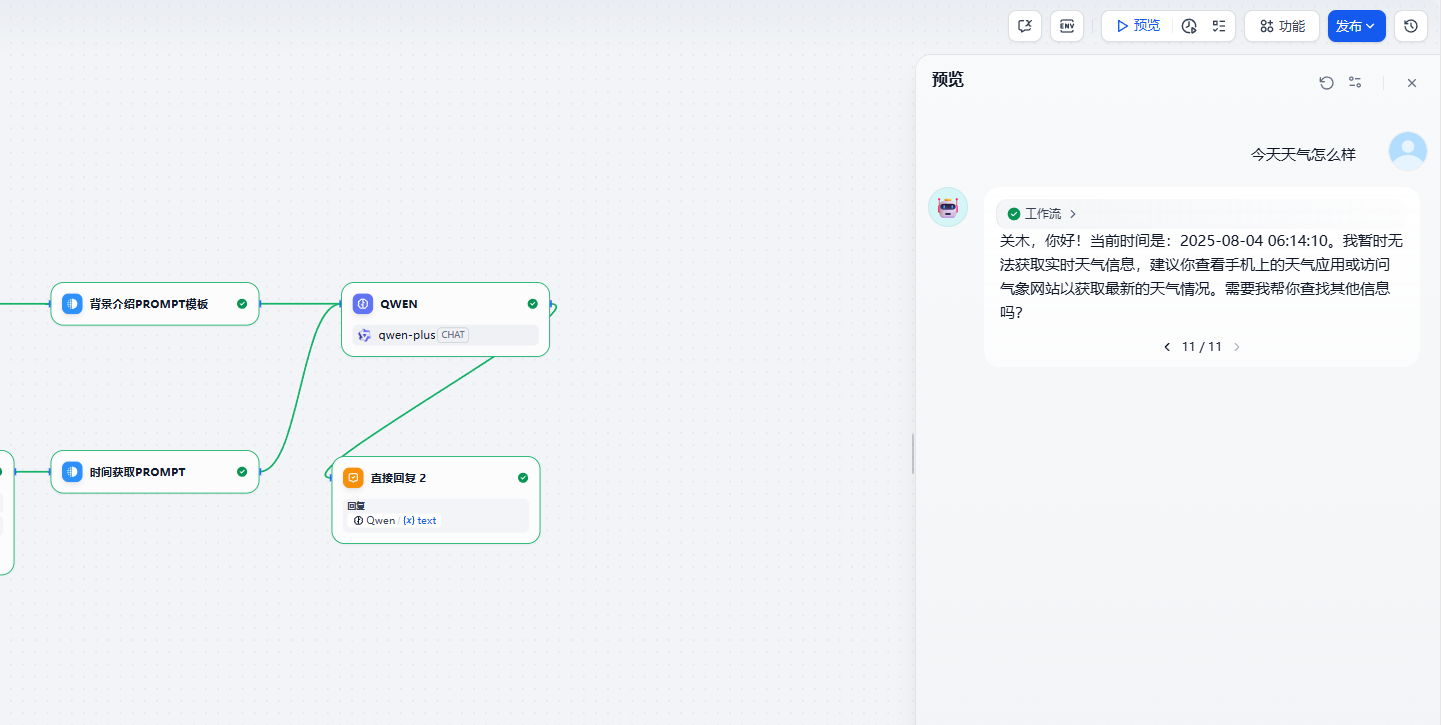
示例5:动态组合Prompt模板在一个LLM中使用
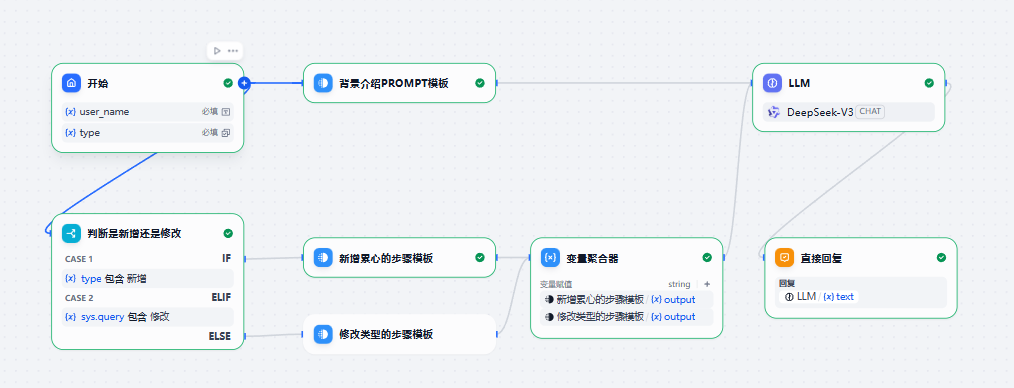
针对不同的使用类型,我们希望能够复用一些提示词。例如我希望新增和修改合同的步骤不一样,但是要求是一样。
首先,我们先撰写相同部分:
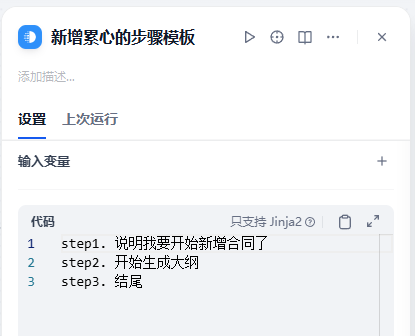
接着我们撰写不同类型任务针对的不同Prompt
例如新增合同的步骤:
再增加修改合同的步骤:
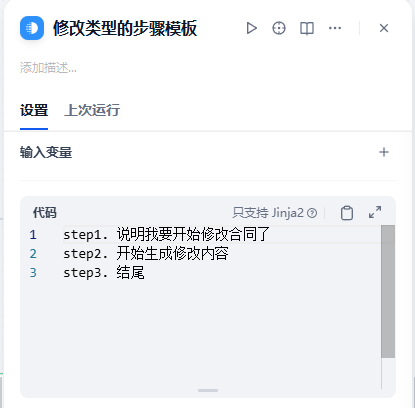
最后,我们将Prompt 进行整合
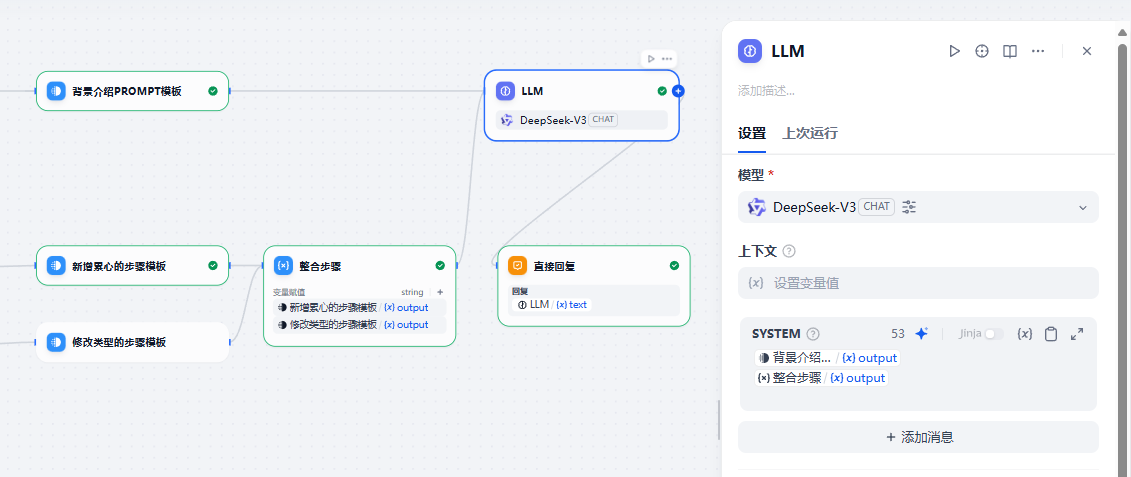
最后,我们进行调试:
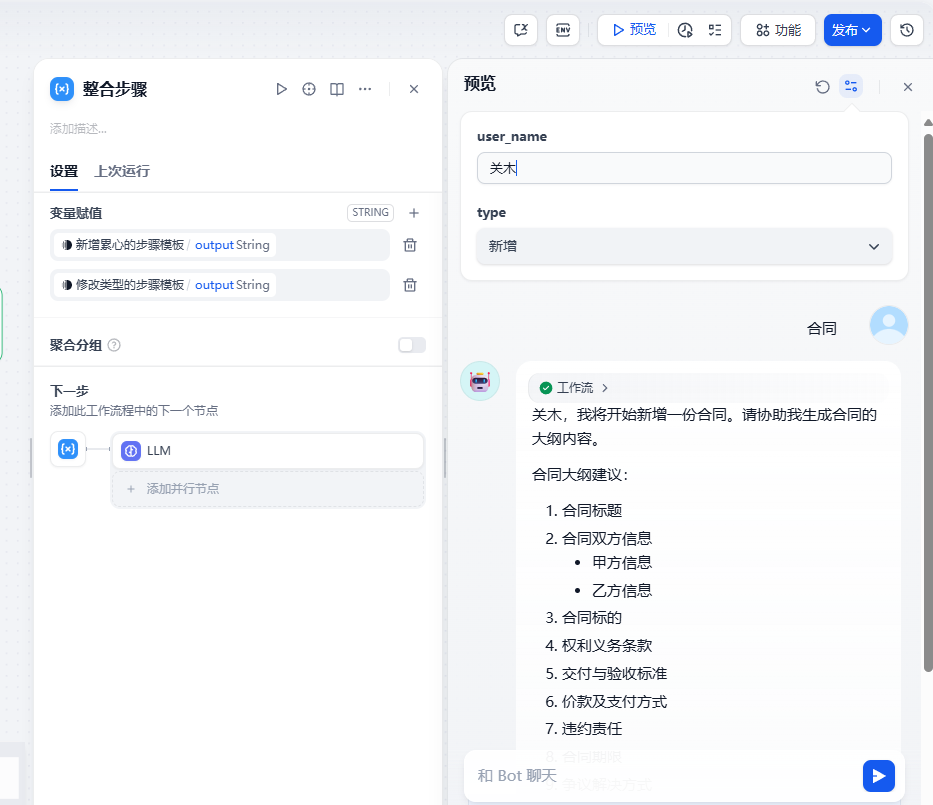
我们通过动态的方式搭建了一个动态Prompt 的工作流。
示例6:Prompt动态生成嵌套使用
这是一种更高阶的用户,各个提示词不仅可以在LLM节点汇聚,也可以在模板节点进行组合嵌套。
我们可以
- 将提示词的构建封装成Dify的工具,Prompt也需要工程。
- 动态的组合,可以嵌套、可以平级、也可有有逻辑。
- 基于Jinja2语法,代码可以实现的组合判断都能实现
总结:
通过模板转换节点可以方便的帮我们进行Prompt 的管理,但是他同时也带来了很多问题
- Prompt的组合和拼接会带来性能问题,需要平衡收益。
- 调试节点会增多,可能会对调试造成困扰
每一种方案都有利弊,重要的是权衡。